728x90
반응형
SMALL
RAG는 정보 검색과 생성을 결합한 모델로, 대량의 텍스트 데이터로부터 정보를 추출하고 이를 기반으로 새로운 텍스트를 생성하는 기술입니다. RAG는 GPT(Generative Pre-trained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)와 같은 대형 언어 모델을 기반으로 하며, 정보 검색 및 생성의 두 가지 기능을 통합하여 텍스트 이해와 생성의 품질을 향상시킵니다.
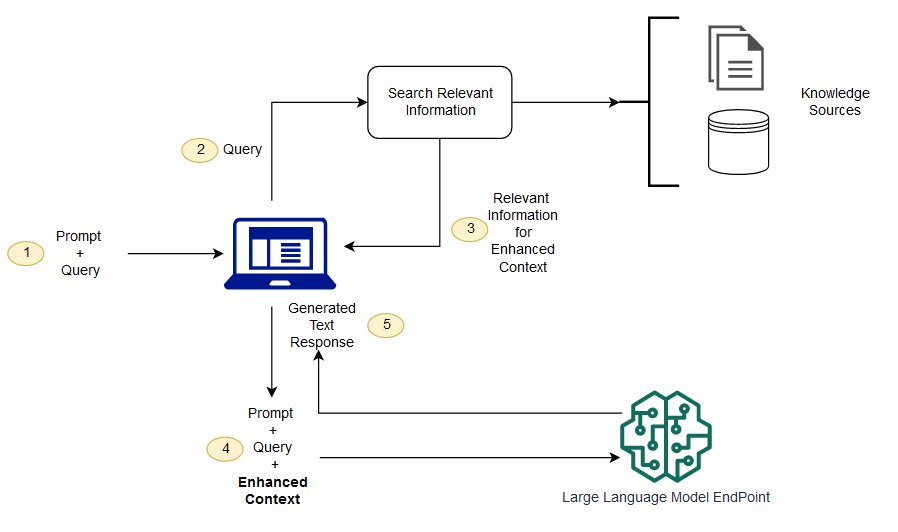
RAG의 주요 특징 및 작동 원리:
- 검색 기능: RAG는 텍스트 검색을 위해 BM25나 TF-IDF와 같은 전통적인 정보 검색 기법을 사용합니다. 이를 통해 대량의 텍스트 데이터에서 관련성 높은 문서나 정보를 식별할 수 있습니다.
- 추출 기능: 검색된 문서에서 특정 정보나 텍스트를 추출하는 기능을 제공합니다. 예를 들어, 특정 질문에 대한 답변으로 필요한 정보를 추출합니다.
- 생성 기능: 추출된 정보를 기반으로 새로운 텍스트를 생성합니다. 이때 대형 언어 모델을 사용하여 문장을 자연스럽게 생성하고 다양한 주제나 스타일에 맞게 텍스트를 조정합니다.
- 재검색 및 반복: 생성된 텍스트는 다시 검색에 사용될 수 있으며, 이를 통해 더 나은 정보 검색 및 생성이 가능해집니다.
RAG의 활용:
- 질문 응답(Question Answering): RAG는 특정 질문에 대한 답변을 생성하고, 필요한 정보를 검색하여 답변의 정확성과 완성도를 높입니다.
- 요약(Summarization): RAG는 대량의 텍스트 데이터에서 요약을 추출하고, 이를 기반으로 간결하고 의미 있는 요약을 생성합니다.
- 콘텐츠 생성(Content Generation): RAG는 주제에 대한 자유로운 글쓰기나 텍스트 생성을 지원하며, 검색된 정보를 활용하여 새로운 콘텐츠를 생성합니다.
RAG의 장점:
- 정보 품질 향상: 검색과 생성을 결합함으로써 정보의 품질과 신뢰성을 향상시킵니다.
- 다양한 활용성: 질문 응답, 요약, 콘텐츠 생성 등 다양한 응용 분야에서 활용할 수 있습니다.
- 자동화 및 효율성: 자동화된 검색과 생성 과정을 통해 인간의 노력을 절약하고 작업의 효율성을 높입니다.
RAG의 한계와 도전 과제:
- 정보 오류: 검색된 정보의 정확성에 대한 보장이 필요합니다.
- 다양성과 일관성: 생성된 텍스트의 다양성과 일관성을 유지하는 것이 중요합니다.
- 성능과 효율성: 대량의 데이터에 대해 빠르고 효율적인 검색과 생성을 지원해야 합니다.
결론:
RAG는 정보 검색과 생성을 결합하여 정보화 기술의 발전과 함께 다양한 응용 분야에서 활용되고 있습니다. 향후 RAG의 발전과 함께 정보 검색 및 생성의 품질을 높이는 데 더 많은 연구와 기술 발전이 기대됩니다.
728x90
반응형
LIST
'IT 이론지식' 카테고리의 다른 글
| 뇌-컴퓨터 인터페이스(BCI, Brain-Computer Interface) (1) | 2024.03.31 |
|---|---|
| LangChain (0) | 2024.03.26 |
| 정보화 전략 계획(ISP: Information Strategic Plan) (1) | 2024.03.26 |
| 클린룸 모델(Cleanroom Model) (0) | 2024.03.26 |
| 소프트웨어 개발 수명주기(SDLC: Software Development Life Cycle) (0) | 2024.03.26 |